Bases del diseño amigable para motores de búsqueda y el desarrollo
Los motores de búsqueda son limitados en cuanto a que es lo que rastrean y cómo interpretan el contenido. Una página web no siempre se ve igual para ti cómo para un motor de búsqueda. En esta sección, nos enfocaremos en los aspectos técnicos específicos. Para construir (o modificar) páginas web estructuradas tanto para motores de búsqueda como para visitantes humanos. Esta es una parte de la guía que es excelente para compartir con tus programadores, arquitectos de la información y diseñadores, de tal manera que todas las partes envueltas en la construcción de un sitio web puedan planificar y desarrollar un sitio web amigable para los motores de búsqueda.
Contenido Indexable
Para poder estar listado en los motores de búsqueda, su contenido más importante debería estar en texto en formato HTML . Imágenes, archivos en flash, aplicaciones Java, y cualquier otro contenido que no sea texto es frecuentemente ignorado o devaluado por las arañas de los motores de búsqueda, a pesar de los avances en tecnología de rastreo. La mejor manera de asegurar que las palabras o frases que muestra en su sitio web a sus visitantes sean visibles para los motores de búsqueda es colocarlos en el texto HTML de su página. De cualquier modo, métodos más avanzados se encuentran disponibles para aquellos que demandan mejores estilos visuales o de forma:
- Imágenes en formato gif, jpg, o png pueden contener atributos "alt" en HTML, brindando a los motores de búsqueda una descripción en texto del contenido visual.
- Las cajas de búsqueda pueden ser sustituaidas por enlaces navegables de navegación.
- Plug ins en flash o java script con contenido pueden ser sustituidos con texto en la página
- Contenido en Video y audio debería tener una transcripción que los acompañe si las palabras y frases son significativas para ser indexadas por los buscadores.
Mirando como un motor de búsqueda
Muchos sitios web tienen significativos problemas para poder indexar su contenido, entonces chequear por partida doble vale la pena, Usando herramientas como el caché de Google, SEO-browser.com, o el MozBar se puede ver qué elementos de su contenido son visibles e indexables por los motores. Eche un vistazo al texto en caché de Google de esta página. Que diferencias puede ver?
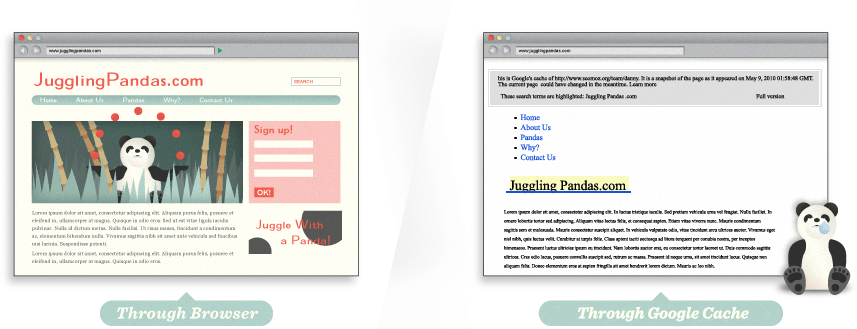
¡Wow! ¿Así es como nos vemos?
Con la función de caché de Google, somos capaces de ver que a un motor de búsqueda, la página principal JugglingPandas.com no contiene toda la riqueza de información que vemos. Esto hace que sea difícil para los motores de búsqueda interpretar la relevancia.
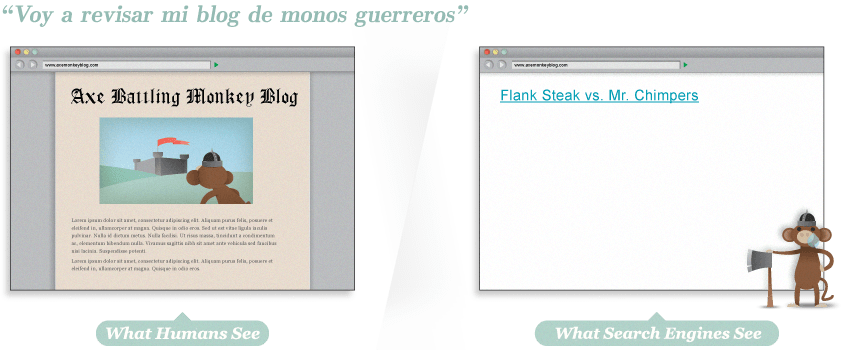
¿Hay un montón de monos y solamente se ve una línea de texto?
Hey, ¿Dónde se fue la diversión?
Eeeh… vía Google cache, podemos ver que la página es tierra estéril. Ni siquiera hay texto que nos diga que la página contiene a los monos guerreros. La página está enteramente construida en flash, pero tristemente, esto significa que los motores de búsqueda no pueden indexar nada del texto contenido, ni siquiera lo enlaces de los juegos individuales. Sin nada de texto HTML, esta página tendría un tiempo bien difícil rankeando en los resultados de búsqueda.
Es sabio no revisar solamente por el contenido en texto sino utilizar las herramientas SEO para chequear doblemente que las páginas que ha hecho sean visibles para los motores de búsqueda. Esto aplica para las imágenes y como vemos abajo, para sus enlaces también.
Estructuras rastreables de enlaces
Al igual que los motores de búsqueda necesitan para ver el contenido con el fin de mostrar las páginas en sus enormes índices basados en palabras clave, también tienen que ver los enlaces con el fin de encontrar el contenido. Una estructura de enlaces rastreable - que permite navegar por sus arañas de las vías de un sitio web - es vital para encontrar todas las páginas en un sitio web. Cientos de miles de sitios cometen el error fundamental de la estructuración de su navegación de manera que los buscadores no pueden acceder, por lo tanto afectando su capacidad para obtener las páginas que figuran en los índices de los buscadores.
Abajo, hemos ilustrado como puede suceder este problema:

En el ejemplo de arriba, la araña de Google ha llegado a la página "A" y ve enlaces hacia las páginas "B" y "E". Sin embargo, incluso a pesar que C y D pueden ser importantes páginas en el sitio, la araña no tiene forma de llegar a ellas (o incluso saber que estas existen). Esto es porque no hay enlaces directos rastreables que apunten hacia estas páginas. En cuanto a Google se refiere, estas bien podrían no existir. Un gran contenido, buena orientación de keywords, y un marketing inteligente no hará ninguna diferencia en absoluto si las arañas no pueden llegar a esas páginas, en primer lugar.
Anatomía de un enlace

En la ilustración de arriba, la etiqueta "<" indica el inicio de una relación. Las etiquetas de vínculos pueden contener imágenes, textos, u otros objetos, todos los cuales disponen de un área en la que los usuarios puede hacer clic dentro de la página para pasar a otra página. Este es el elemento original de la navegación de Internet: los "hipervínculos". La ubicación de referencia del vínculo indica al navegador (y los motores de búsqueda), hacia donde apunta el enlace. En este ejemplo, la dirección http://www.jonwye.com es referenciada. A continuación, la parte visible del enlace para los visitantes, llamado "anchor text" en el mundo SEO, describe la página hacia la que el enlace apunta. La página señalada es sobre cinturones personalizados, hechos por mi amigo de Washington DC, JonWye, así que he utilizado el texto de anclaje "Los cinturones diseñados de encargo de JonWye". El </a> tag cierra el enlace, por lo que los elementos posteriores en la página no tiene el atributo de vínculo que se les aplica.
Este es el formato más básico de un enlace - y ese minentemente comprensible para los motores de búsqueda. Las arañas saben que deben añadir este enlace al gráfico deenlace de los motores de la web, se utiliza para calcularconsulta variables independientes (como el PageRank de Google), y lo siguen para indexar el contenido de la página de referencia.
Echemos un vistazo a algunas razones comunes porqué las páginas no pueden ser encontradas
Formularios de llenado requerido
Si usted requiere que los usuarios completen un formulario on line antes de acceder a cierto contenido, entonces tal vez nunca se pueda acceder a dicho contenido en páginas protegidas. Los formularios podrían incluir un login protegido por una contraseña o unos cuestionarios. En ambos casos, las arañas generalmente no intentarán llenar esos formularios y en consecuencia, ningún contenido o enlaces podrían ser accesibles, siendo invisibles para los motores de búsqueda.
Enlaces en Javascript
Si utiliza JavaScript para los enlaces, es posible que los motores de búsqueda puedan no encontrar o dar muy poco peso a los enlaces incorporados en su interior. Vínculos en HTML debe sustituir al estándar Javascript (o acompañar al mismo) en cualquier página que le gustaría que las arañas rastreen.
Enlaces apuntando hacia páginas bloqueadas por etiquetas meta robots o robots.txt
El meta tag robots y el archivo robots.txt permiten al un propietario de un sitio restringir el acceso de las arañas a una página. Sólo se hay que advertir que muchos webmasters han utilizado sin querer estas directivas sin intención como un intento de bloquear el acceso de robots indeseados, sólo para descubrir que los buscadores han puesto fin a su rastreo.
Frames e I-Frames
Técnicamente, los enlaces tanto en frames como I-Frames son legibles, pero ambos presentan problemas estructurales para los motores de búsqueda en términos de organización y seguimiento. A menos que sea un usuario avanzado con un buen entendimiento técnico de cómo los motores indexan y siguen los enlaces en frames, es mejor de permanecer lejos de ellos.
Los robots no usan formularios de búsqueda
Aunque esto se relaciona directamente con la advertencia anterior sobre los formularios, es un problema tan común que vale la pena mencionar. Algunos webmasters creen que si colocan un cuadro de búsqueda en su sitio, entonces los motores serán capaz de encontrar todo lo que buscan los visitantes . Por desgracia, las arañas no realizar búsquedas para encontrar contenido, y por lo tanto, millones de páginas están escondidas detrás de paredes inaccesibles, condenadas al anonimato hasta en el caso que otras páginas rastreadas las enlacen.
Enlaces en flash, java u otros plug-ins
El caso de los enlaces incrustados en el interior del sitio de Panda (ennuestro ejemplo anterior) es una perfecta ilustración de este fenómeno. Aunque decenas de pandas se enumeren y vinculen hacia la página de Panda, ninguna araña puede llegar a ellos a través de la estructura de enlaces del sitio, lo que hace invisibles las páginas a los motores (y no listables por los buscadores si se realiza una consulta).
Enlaces hacia páginas con varios cientos o miles de enlaces
Las arañas de los motores de búsqueda sólo siguen un número determinado de enlaces en una página concreta : no es una cantidad infinita. Esta restricción se suelta es necesario reducir el spam y conservar los rankings. Las páginas con más de 100 enlaces en ellas se encuentran en riesgo de no conseguir todos esos enlaces rastreado e indexado.
Si usted evita caer en estas trampas, tendrá un enlaces en html encontrables que permitirán a las arañas acceder fácilmente a las páginas de contenido de su site.

rel="nofollow" puede ser utilizado con la siguiente sintaxis:
<a href="http://moz.com" rel="nofollow">Lousy Punks!</a>
Los enlaces pueden tener muchos atributos aplicados a ellos, pero los motores ignoran casi todas ellas, con la importante excepción de la rel = "nofollow". En el ejemplo anterior, añadiendo el atributo rel = nofollow a la etiqueta del enlace, le decimos a los motores de búsqueda que nosotros, los propietarios del sitio, no queremos que este enlace se interprete como el normal "voto editorial".
El atributo "nofollow", tomado literalmente, es la instrucción para los motores de búsqueda de no seguir un enlace (aunque algunos lo hacen.) La etiqueta "nofollow" surgió como un método para ayudar a detener los comentarios automatizados en blogs, libros de visitas, y todo tipo de spam (leer más aquí), pero se ha transformado con el tiempo en una forma de decirle a los motores que descarte cualquier valor de vínculo que normalmente se transmiten. Los enlaces con la etiqueta nofollow son interpretados de forma ligeramente diferente por cada uno de los motores, pero está claro que no pasan tanto peso como los normales.
¿Son los enlaces "nofollow" malos?
A pesar de que no pasan tanto valor como sus primos"follow", los enlaces "nofollow" son una parte natural del diverso perfil de enlaces que podemos encontrar en cualquier sitio web. Un sitio web con un montón de enlaces entrantes acumulará muchos enlaces nofollow, y esto no es una cosa mala. De hecho, los factores de clasificación de SEOmoz mostraron que los sitios de alto rango tienden a tener un mayor porcentaje de enlaces entrantes nofollow que los sitios de menor rango.
Google
Google afirma que en la mayoría de los casos, no siguen los enlaces nofollow, ni hacen que estos enlaces hagan transferencia de PageRank o los valores de los textos ancla. Esencialmente, utilizando nofollow nos hace caer del objetivo de los vínculos de nuestro gráfico general de la web. Los enlaces nofollow no tienen ningún peso y se interpretan como texto HTML (como si el vínculo no existiría). Dicho esto, muchos webmasters creen que incluso enlaces nofollow de de sitios de alta autoridad, como Wikipedia, podría ser.
Bing y Yahoo!
Bing, que potencia los resultados de búsqueda de Yahoo, también ha declarado que no se incluyen los enlaces nofollow en el gráfico de enlaces. En el pasado, han indicado también que los enlaces nofollow todavía puede ser utilizados por sus bots para descubrir nuevas páginas. Así, mientras que "pueden" seguir los enlaces, no van a contar con ellos para brindar un impacto positivo en ranking.
Uso de las keywords y "targeting"
Las palabras clave son fundamentales para el proceso de búsqueda; son los componentes básicos del lenguaje y la búsqueda. De hecho, toda la ciencia proporcionar los resultados de búsqueda información (incluidos los motores de búsqueda basados en web como Google) se basa en keywords. A medida que las arañas de los motores visitan e indexan los contenidos de las páginas en la web, hacen un seguimiento de las páginas indexadas basado en keywords. Así, en lugar de almacenar 25 millones de páginas web todo en una base de datos, los motores tienen millones y millones de pequeñas bases de datos, cada una centrada en un término o particular palabra clave o frase en particular. Esto hace que sea mucho más rápido para los motores recuperar los datos que necesitan en una mera fracción de segundo.
Obviamente, si usted quiere que su página tenga la oportunidad de posicionarse en los resultados de búsqueda para "perro", es prudente asegurarse de que la palabra "perro" sea parte del contenido indexable de su documento.
Dominancia de Keywords
Las keywords dominan nuestra intención de búsqueda y la interacción con los motores de búsqueda. Por ejemplo, un patrón común de podría ser algo como esto:
Cuando se realiza una búsqueda, el motor de búsqueda empata páginas para recuperar las páginas basadas en las keywords introducidas en el cuadro de búsqueda. Otros datos, como el orden de las palabras ("discos de rock" frente a "rock discos"), la ortografía, puntuación, y la capitalización de las keywords proporcionan información adicional que los motores utilizan para ayudar a recuperar las páginas correctas y clasificarlas.
Para ayudar a lograr esto, los motores de búsqueda miden la manera en que las palabras clave se utilizan en las páginas para ayudar a determinar la "pertinencia" de un documento en particular en relación una consulta. Una de las mejores maneras de "optimizar" el ranking de una página es asegurarse que las palabras clave se utilicen prominentemente en títulos, texto y "metadata" de la página.
En general, cuanto más específicas sean sus palabras clave, mejores serán sus posibilidades de ranking debido a que se enfrentará a una menor competencia. El mapa gráfico de la izquierda muestra la importancia de los libros generales plazo para el título específico, Historia de dos ciudades. Tenga en cuenta que si bien hay una gran cantidad de resultados (del tamaño de un país) para un término amplio, se producen mucho menos resultados y por lo tanto, menos competencia para los resultados específicos.
Abuso de las keywords
Desde los albores de la búsqueda en línea, la gente ha abusado de las keywords en un esfuerzo equivocado para manipular los resultados de búsqueda. Esto incluye las tácticas de "relleno" de palabras clave en el texto, URL, meta tags y enlaces. Por desgracia, en vez de ayudar, esto casi siempre hace más daño a su sitio.
En sus primeros días, los motores de búsqueda se basaron en el uso de keywords como señales de relevancia primordial, independientemente de si estas keywords se habían usado efectivamente.
Hoy en día, aunque los motores de búsqueda aún no pueden leer y comprender el texto, tal como lo haría un ser humano, el avance de la tecnología les ha permitido acercarse a este ideal.
La mejor práctica es utilizar las palabras clave de forma natural y estratégica (más sobre esto más adelante). Si la página está orientada hacia la frase de palabras clave "Torre Eiffel", entonces, naturalmente, debería incluir contenido sobre la Torre Eiffel en sí: la historia de la torre, o incluso recomendado de hoteles en París. Por otro lado, simplemente rociar una página de contenido irrelevante (por ejemplo una página sobre perros) con las palabras "Torre Eiffel", sus esfuerzos para clasificar en una posición relevante para la "Torre Eiffel" será una batalla larga y cuesta arriba.
Optimización On Page
Dicho lo anterior, el uso de keywords y la orientación son todavía una parte de los algoritmos de ranking de los buscadores, y podemos aprovechar algunas "buenas prácticas" efectivas en el uso de keywords para ayudar a crear páginas que estén cerca de lo "optimizado".
Aquí, en SEOmoz, hemos llevado a cabo muchas pruebas para poder llegar a ver un gran número de resultados búsqueda y los cambios basados en tácticas de uso de palabras clave. Cuando trabaje con uno de sus propios sitios, este es el proceso que recomendamos:
- Usar la palabra clave en la etiqueta del título al menos una vez. Trate de mantener la palabra tan cerca del comienzo de la etiqueta del título como sea posible. Podrá encontrar más detalles sobre las etiquetas de título adelante en esta sección.
- Una vez colocadas prominentemente cerca de la parte superior de la página.
- Deben repetirse por lo menos 2-3 veces, con variantes, en el cuerpo del texto en la página, a veces algunas veces más si hay una gran cantidad de contenido de texto.
- Se puede encontrar un valor adicional colocando más veces la palabra clave o sus variaciones, pero en nuestra experiencia, la adición de más veces de un término o frase tiende a tener poco o ningún impacto en las clasificaciones.
- Al menos una vez en el atributo alt de una imagen en la página. Esto no sólo ayuda con la búsqueda en la Web, sino también la búsqueda de imágenes, que en ocasiones puede traer tráfico valioso.
- Una vez en la URL. Normas adicionales para las direcciones URL y las palabras clave Se tratarán más adelante en esta sección.
- Por lo menos una vez en la meta etiqueta "description" . Nótese que la meta etiqueta "description" no es tomada en cuenta por los motores de búsqueda para las clasificaciones, sino que ayuda a atraer clics por buscadores de la página de resultados, ya que es un extracto del texto utilizado por los motores de búsqueda.
- Por lo general, no en el texto de texto ancla en la propia página que apunta a otras páginas en su sitio web o dominios diferentes (esto es un poco complejo - ver esta entrada del blog para más detalles).
El mito de la densidad de Keywords
La densidad de palabras clave no forma parte del algoritmo moderno de los motores de búsqueda, como se demostró en The Keyword Density of Non-Sense del Dr. Edel García.
Si dos documentos, D1 y D2, se componen de 1.000 términos (l =1000) y se repite un término20 veces (tf = 20), y luego un analizador de densidad de palabras clave le dice que para ambos documentos la densidad de palabras clave (KD) KD = 20/1000 =0,020 (o 2%) para ese término.
Valores idénticos se obtiene cuando tf = 10 y L = 500. Evidentemente, un analizador de densidad de keywords no establece que el documento es más relevante. Un análisis de densidad de palabras clave relación no nos dice nada acerca de:
- La distancia relativa entre las palabras clave en los documentos
- Cuando en un documento, los términos se producen (distribución)
- La frecuencia de co-citación entre los términos (co-ocurrencia)
- El tema principal, el tema y subtemas (en tema de números)
La conclusión:
La densidad de palabras clave está divorciada de contenido, calidad, semántica, y la relevancia.
¿Cómo debería verse una página con una densidad de Keyword óptima entonces?
Una página ideal para la frase "zapatillas", sería algo así como:

Usted puede leer más información sobre Optimización On page en este post.
Etiqueta de Título <title>
El elemento de título de una página pretende ser una descripción exacta y concisa de los contenidos de una página. Es muy importante tanto para la experiencia del usuario como para la optimización de motores de búsqueda.
Como las etiquetas de título son una parte tan importante para el SEO, las siguientes buenas prácticas para la creación de la etiqueta del título constituyen lo mejor que podemos hacer sin tanto esfuerzo para obtener mejores resultados de posicionamiento.
Las siguientes recomendaciones cubren las partes críticas de la optimización de las etiquetas de título tanto para el motor de búsqueda como para los objetivos de usabilidad.
Sea consciente de la longitud
Los motores de búsqueda sólo pueden ver los primeros 65-75 caracteres de un título en los resultados de búsqueda. (Después de esta longitud, muestran puntos suspensivos - "..." para indicar que una etiqueta de título ha sido cortada) Este es también el límite general permitido por la mayoría de los sitios de medios sociales, por lo que tomar en cuenta este límite es conveniente en general.
Sin embargo, si usted está apuntando a múltiples palabras clave (o una frase de palabras clave, especialmente larga) y tenerlos en la etiqueta del título es esencial para el ranking , puede ser aconsejable pasarse el límite de palabras del título.
Coloque las palabras clave más importantes cerca en la parte delantera
Cuanto más cerca del comienzo de la etiqueta del título se encuentren las keywords, más útil serán para el ranking y es más probable que un usuario hará clic en en los resultados de búsqueda.
Apalancamiento de marca
En SEOmoz, nos encanta poner fin a todas las etiquetas del título con el nombre de la marca, ya que éstas ayudan a aumentar la conciencia de marca, y crear un mayor porcentaje de clics para las personas que les gusta y están familiarizados con una marca.
A veces tiene sentido para colocar su marca en el comienzo de la etiqueta del título, como su página de inicio. Puesto que las palabras al comienzo de la etiqueta del título tienen más peso, hay que ser conscientes de lo que usted está tratando de clasificar.
Tenga en cuenta la legibilidad y el impacto emocional
Las etiquetas del título deben ser descriptivas y fáciles de leer. La creación de una etiqueta de título convincente atraerá un mayor número de visitas de los resultados de búsqueda a su sitio.
Por lo tanto, es importante no sólo pensar en la optimización y uso de palabras clave, sino en la experiencia del usuario. La etiqueta del título es la primera interacción de un visitante nuevo con su marca y debe dar la impresión más positiva posible.
Buenas prácticas para colocar meta etiquetas de título.
The title tag of any page appears at the top of Internet browsing software, and is often used as the title when your content is shared through social media or republished.
Using keywords in the title tag means that search engines will "bold" those terms in the search results when a user has performed a query with those terms. This helps garner a greater visibility and a higher click-through rate.
La última razón importante para crear palabras clave descriptivas, y cargarlas en las etiquetas de los titles es para rankear en los resultados de los motores de búsqueda. En la encuesta bianual de SEOmoz a los líderes de la industria de SEO, el 94% de los participantes dijo que el lugar más importante para la utilización de palabras clave para alcanzar altas posiciones era la etiqueta del título.
Meta Tags
Los meta tags fueron pensados originalmente para proporcionar un proxy para brindar información sobre el contenido de un sitio web. Varias de las etiquetas meta básicas se enumeran a continuación, junto con una descripción de su uso.
Meta Robots
La etiqueta meta robots pueden utilizarse para controlar la actividad de las arañas del motor de búsqueda (de los buscadores más importantes) en un nivel de página. Hay varias maneras de utilizar robots meta para controlar cómo los motores de búsqueda tratan a una página:
- Índice / noindex le dice a los motores si la página debe ser rastreada y mantenerse en el índice de los motores para la recuperación en lás búsquedas. Si opta por usar "noindex", la página será excluida de los buscadores. De forma predeterminada, los motores de búsqueda asumen que puede indexar todas las páginas, así que usar el valor "índice" es generalmente innecesario.
- follow/nofollow le dice a los motores si los enlaces de la página deben ser rastreados. Si usted opta por emplear "nofollow", los motores no tendrán en cuenta los enlaces de la página, tanto para el descubrimiento como para propósitos del ranking. Por defecto, se asume que todas las páginas tienen el atributo "follow". Ejemplo:
<META NAME="ROBOTS" content="NOINDEX, NOFOLLOW">
- No archive se utiliza para restringir a los motores de búsqueda de guardar una copia en caché de la página. De forma predeterminada, los motores mantiendrán copias visibles de todas las páginas indexadas, accesibles a los buscadores a través de un vínculo de"caché" que aparece en los resultados de búsqueda.
- No snippet informa a los motores que deben abstenerse de mostrar un bloque de texto descriptivo al lado del título de la página y el URL en los resultados de búsqueda.
- Noodp / noydir son etiquetas especializadas que les dicen a los motores que no tomen un fragmento descriptivo de una página del Open Directory Project (DMOZ) o el Directorio de Yahoo! para mostrar en los resultados de búsqueda.
La directiva de la etiqueta X-Robots HTTP que se coloca en el header también cumple con estos mismos objetivos. Esta técnica funciona especialmente bien para el contenido dentro de los archivos no HTML, como son las imágenes.
Meta Description
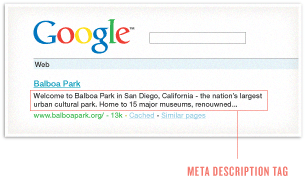
La etiqueta meta description existe como una breve descripción del contenido de una página. Los motores de búsqueda no utilizan las palabras clave o frases en esta etiqueta para las clasificaciones, pero las meta descripciones son la fuente primaria para componer el fragmento de texto que aparece debajo de un anuncio en los resultados.
La etiqueta meta descripción cumple la función de un texto publicitario para atraer a los lectores a su sitio en los resultados y por lo tanto, es una parte muy importante de marketing en buscadores. La elaboración de una descripción legible y convincente con las palabras clave importantes (nótese cómo Google "pone en negrita" las palabras clave buscadas en la descripción) puede traducirse en una mucho mayor tasa de click-through a su página.
Las Meta Descripciones puede tener cualquier longitud, pero los motores de búsqueda generalmente cortan fragmentos de más de 160 caracteres, por lo que es conveniente en general permanecer en estos límites.
En caso de la ausencia de meta descripciones, los motores de búsqueda van a crear una de otros elementos de la página. Para las páginas que se dirigen a varias palabras clave y temas, esta es una táctica perfectamente válido.
Meta etiquetas no tan importantes
Meta Keywords
La meta etiqueta de keywords tuvo valor alguna vez, pero ya no es valioso o importante para SEO. Para más información sobre la historia y una explicación completa de por qué la metaetiqueta de keywords ha caído en desuso,lea Meta Tag keywords 101 de SearchEngineLand.
Meta refresh, meta revisit-after, meta content type, etc.
A pesar de estas etiquetas puede tener usos para la optimización de motores de búsqueda, que son menos críticos para el proceso, se lo dejaremos a las Herramientas para webmasters de Google para responder con mayor detalle: Meta Tags.
Estructuras de URL
La URL, la dirección Web de un documento en particular, es de gran valor desde una perspectiva de búsqueda. Aparecen en varios lugares importantes.

Dado que los motores de búsqueda muestran las direcciones URL en los resultados, estas pueden tener impacto de click-through y la visibilidad. Las URLs también se utilizan en los documentos de clasificación, y esas páginas cuyos nombres incluyan los términos de búsqueda consultados recibe algún beneficio de un uso adecuado y descriptivo de las palabras c

El URL hace una aparición en la barra de direcciones del navegador web, y si bien por regla general, tiene poco impacto en los motores de búsqueda, una estructura de dirección y diseño pobres puede resultar en experiencias de usuario negativas.
La dirección de arriba se utiliza como el texto ancla del enlace que apunta a la página de referencia en esta entrada del blog.
Pautas para construir URLs
Emplee empatía
Póngase en la mente de un usuario y vea su dirección URL. Si usted puede fácil y predecir con precisión el contenido que usted esperaría encontrar en la página, las direcciones URL son apropiadamente descriptivos. Usted no necesita explicar todos los detalles en la URL, pero poner una idea es un buen punto de partida.
Más corto es mejor
Mientras que una dirección URL descriptiva es importante, minimizar la longitud al final hará que su URL sea fácil de copiar y pegar (en correos electrónicos, blogs, mensajes de texto, etc) y será totalmente visible en los resultados de búsqueda.
El uso de palabras clave es importante (pero el uso excesivo es peligroso)
Si su página tiene como objetivo un término o frase específica, asegúrese de incluirlos en la URL. Sin embargo, no se vaya por la borda tratando de meter en varias palabras clave para fines de SEO. Un uso excesivo, hará que la URL sea menos utilizable y puede ser atrapada por los filtros de spam.
Tiene que ser estática
Las mejores direcciones URL son legibles sin un montón de parámetros, números y símbolos. El uso de tecnologías como mod_rewrite para Apache y ISAPI_Rewrite de Microsoft, usted puede fácilmente transformar las URLs dinámicas como esta www.seomoz.org/blog?id=123 en una versión estática más fácil de leer así: http://www.seomoz.org/blog / google-fresco-factor. Incluso los parámetros dinámicos individuales en una dirección URL puede resultar en una menor clasificación general y la indexación.
Manténga una URL estática
Las mejores direcciones URL son legibles sin un montón de parámetros, números y símbolos. Utilizando tecnologías como mod_rewrite para Apache y ISAPI_Rewrite de Microsoft, usted puede fácilmente transformar las URLs dinámicas como esta www.seomoz.org/blog?id=123 en una versión estática más fácil de leer así: http://www.seomoz.org/blog / google-fresco-factor. Incluso los parámetros dinámicos individuales en una dirección URL puede resultar en un menor ranking general e indexación.
Use hyphens para separar palabras
No todas las aplicaciones web son capaces de interpretar correctamente los separadores como el subrayado "_", más "+", o en el espacio "20%", por lo cual, es mejor utilizar el guión "-" para separar las palabras en una URL.
Canonización y versiones duplicadas de contenido
El contenido duplicado es uno de los problemas más difíciles y problemáticos de cualquier sitio web puede enfrentar. En los últimos años, los motores de búsqueda han tomado medidas enérgicas contra el contenido duplicado a través de sanciones y rankings más bajas.
La canonización sucede cuando dos o más versiones duplicadas de una página web aparecen con diferentes direcciones URL. Esto es muy común con los modernos sistemas de gestión de contenidos. Por ejemplo, puede ofrecer una versión regular de una página y una "versión optimizada" para impresión con los mismos contenidos. El contenido duplicado puede incluso aparecer en varios sitios web. Para los motores de búsqueda, esto representa un gran problema - ¿Cuál versión de este contenido se muestran en las búsquedas? En los círculos de SEO, esta cuestión se refiere a menudo como contenido duplicado, descrita con más detalle aquí.

Los motores de búsqueda son muy exigentes acerca de las versiones duplicadas de una sola pieza de contenido. Para proporcionar la mejor experiencia de búsqueda, rara vez muestran piezas múltiples, duplicados de contenido y, por tanto, se ven obligados a elegir la versión que es más probable que sea el original. El resultado final es que TODO su contenido duplicado podría rankear menos de lo que debería.

Canonización es la práctica de la organizar su contenido de tal manera que cada pieza única tiene una y sólo una dirección URL. Si usted deja varias versiones de contenido en una página web (o páginas web), que podría terminar con un escenario como el de la derecha. ¿Qué diamante es la correcta?

En cambio, si el propietario del sitio cogió esas tres páginas y les aplicó una redirección 301-hacia la página "verdadera", los motores de búsqueda ya sabrán cual es la página de ese sitio más fuerte para mostrar en las listas de resultados.
Cuando múltiples páginas con el potencial de rankear bien son combinadas en una sola página, estas no solamente dejan de competir entre ellas sino crean una relevancia más fuerte y popularidad sobre todo. Esto impactará positivamente en su habilidad de rankear bien en los motores de búsqueda.
¡La etiqueta canónical al rescate!
Una opción diferente de los motores de búsqueda, llamada el "Tag URL canónica" es otra manera de reducir los casos de contenido duplicado en un solo sitio y canonizar a una URL individual. Esto también se puede utilizar entre diferentes sitios web, a partir de una URL en un dominio hacia una dirección URL diferente en un dominio diferente.
Utilice la etiqueta canónica dentro de la página que contiene el contenido duplicado. El "objetivo" de la etiquetas canónica debe apuntar a la dirección URL "maestra" que desea posicionar en la lista de resultados.
El funcionamiento interno
<link rel="canonical" href="http://moz.com/blog"/>
Esto le dice a los motores de búsqueda que la página en cuestión debe ser tratada como si se tratara de una copia de la URL www.seomoz.org / blog y que todas las mediciones del enlace y de contenidos que los motores de búsqueda aplican deben fluir hacia a esa URL.
The Canonical URL tag attribute is similar in many ways to a 301 redirect from an SEO perspective. In essence, you're telling the engines that multiple pages should be considered as one (which a 301 does), without actually redirecting visitors to the new URL - often saving your development staff considerable heartache.
For more about different types of duplicate content, this post by Dr. Pete deserves special mention.

Rich Snippets
¿Ha visto alguna vez una calificación de 5 estrellas en un resultado de búsqueda? Lo más probable es que el motor de búsqueda recibió esa información de fragmentos enriquecidos integrados en la página web. Los fragmentos enriquecidos son un tipo de datos estructurados que permiten a los webmasters marcar el contenido para proporcionar cierta información a los motores de búsqueda.
Mientras que el uso de fragmentos enriquecidos y los datos estructurados no son elementos necesario del diseño amigable para los motores de búsqueda, su creciente adopción significa que los webmasters que los aprovechan puedan estar disfrutando de sus ventajas en algunas circunstancias.
Los datos estructurados conllevan la adición de etiquetas para el contenido de modo que los buscadores puedan identificar fácilmente de qué tipo de contenido se trata. Schema.org ofrece varios tipos de ejemplos de datos que pueden beneficiarse de marcado estructurado. Estos incluyen a personas, productos, reviews,negocios, recetas y eventos.
A menudo, los motores de búsqueda incluyen datos estructurados en los resultados de búsqueda, como en el caso de los comentarios de los usuarios (las estrellas) y los perfiles de autor (fotografías.) Hay varios buenos recursos para aprender más acerca de fragmentos ricos en línea, incluyendo la información en Schema.org y de Google herramienta de prueba de rich snippet.
Rich Snippets in the Wild
Digamos que usted anuncia una conferencia de SEO en tu blog. En HTML normal, el código podría tener este aspecto:
<div>
SEO Conference<br/>
Learn about SEO from experts in the field.<br/>
Event date:<br/>
May 8, 7:30pm
</div>
Ahora, mediante la estructuración de los datos, podemos decir a los motores de búsqueda información más específica sobre el tipo de datos que contiene la página. El resultado final podría tener este aspecto:
<div itemscope itemtype="http://schema.org/Event">
<div itemprop="name">SEO Conference</div>
<span itemprop="description">Learn about SEO from experts in the field.</span>
Event date:
<time itemprop="startDate" datetime="2012-05-08T19:30">May 8, 7:30pm</time>
</div>
Defendiendo el honor de su sitio web
¿Cómo "scrapers" roban sus clasificaciones?
Por desgracia, la web está llena de cientos de miles (o millones) de sitios web sin escrúpulos cuyo modelos de negocio y de tráfico dependen de arrancar el contenido de otros sitios y volver a usarlos (a veces modificados de manera extraña) en sus propios dominios. Esta práctica de ir a buscar a su contenido y volver a publicar-se llama "scraping", y muchas veces los que la llevan a cabo generan ingresos muy buenos, incluso superando a los sitios originales mediante la publicación de anuncios (irónicamente, a menudo de AdSense, el propio programa de Google).
Al publicar el contenido en cualquier tipo de formato de alimentación - RSS / XML / etc -, asegúrese de hacer ping a los principales blogs / servicios de seguimiento (como Google, Technorati, Yahoo, etc.) Puede encontrar instrucciones sobre cómo hacer ping a servicios como Google y Technorati directamente desde sus sitios web, o utilizar un servicio como Pingomatic para automatizar el proceso. Si su software de publicación está hecho a la medida, lo típicamente sabio para los desarrolladores es incluir el auto-ping a la publicación.
A continuación, puede utilizar la pereza de los scrappers en su contra. La mayoría de los scrappers volverán a publicar el contenido sin editar, y por lo tanto, mediante la inclusión de enlaces a su sitio, y un mensaje específico escrito por usted, puede asegurarse de que los motores de búsqueda vean que la mayoría de los textos enlazan de nuevo a su sitio (lo que indica que su sitio es probablemente la fuente original). Para ello, tendrá que utilizar el absoluto, en lugar de que los vínculos relativos en la estructura interna de enlaces . Así, en lugar de vincular a su página principal con:
<a href="../">Home</a>
En su lugar, se debería utilizar:
<a href="http://www.seomoz.org">Home</a>
De esta manera, cuando un raspador recoge y traslada el contenido, el vínculo se mantiene apuntando a su sitio.
Hay formas más avanzadas de protección contra el scrapping, pero ninguna de ellas son totalmente a prueba de tontos. Usted debe esperar que mientras más popular y visible se vuelve su sitio, más a menudo encontrará que su contenido es robado y vuelto a publicar. Muchas veces, usted puede pasar por alto este problema, pero si se pone muy grave, y se encuentra con que los scrappers le quitan su posicionamiento y tráfico, sea posible considerar el uso de un proceso legal llamado DMCA. Por suerte, dentro del propio SEOmoz, una de las abogadas internas Sarah Bird, ha sido autor de una brillante pieza muy útil para resolver este mismo problema. Cuatro maneras de hacer cumplir los Derechos de Autor: ¿Qué hacer cuando su contenido en línea está siendo robada.