PREDICE LOS ABANDONOS DE TU SITIO CON GOOGLE ANALYTICS
![]()
Google Analytics es una herramienta fundamental para una estrategia de marketing digital. Esta plataforma puede ayudarnos a predecir los abandonos de un sitio web y por lo tanto, emplear la estrategia necesaria para que esto no ocurra.
Mientras tenemos cientos de dimensiones y métricas disponibles para explorar en las herramientas de analítica, desafortunadamente no contamos con cientos de horas al mes para explotar esta data y transformarla en información útil para el negocio. Nuestro tiempo se limita a priorizar tareas, revisar y analizar la data que podemos inmediatamente transformar en acciones.
Con esto en mente, me propongo a dar un caso de uso donde se usan datos de una tienda online real y operativa para armar un modelo estadístico que nos ayude a predecir una variable de Google Analytics.
Objetivo principal del caso
Predecir la cantidad de abandonos del funnel (cantidad de visitantes que entran al flujo de un embudo de conversión y lo abandonan).
Objetivo secundario
El modelo tiene que ser un Producto Mínimo Viable; es decir, el modelo tiene que ser estadísticamente significativo, pero no se va a optimizar ni tampoco buscar la mejor alternativa para evaluar los datos y se tiene que entregar en la mínima cantidad de tiempo posible. Le dejaremos esta parte a los de BI.
Después de todo, queremos probar que “en poco tiempo” se puede obtener información que ayude al negocio a tomar acciones de marketing que obedezcan la estrategia del negocio.
Ya que vamos a usar estadística, recordemos un poco el método científico.



OBSERVACIÓN
Probablemente esta es la etapa más larga en todo el proceso pues tenemos que revisar las dimensiones y métricas hasta encontrar alguna tendencia o relación entre variables.
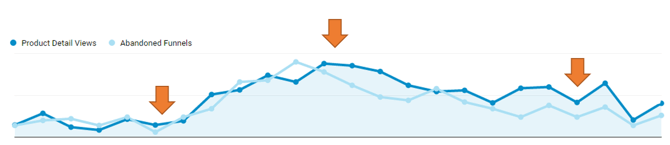
En este caso específico, la tendencia demuestra que existe una relación directa entre la cantidad de vistas de detalle de producto y la cantidad de abandonos del embudo de conversión.
La segunda parte de la observación consiste en obtener las estadísticas descriptivas de las variables (métricas y dimensiones) a analizar.

Señalo las que, según la experiencia trabajando con el negocio, parecen reales. Por ello, en algunos casos usaré la mediana como referencia y en otros la media.
Aquí probablemente hay outliers que sesgan un poco los datos, pero de acuerdo con el objetivo de este experimento vamos a trabajar con lo que tenemos.


Un modo de acortar el tiempo de esta etapa es plantear las variables a analizar en base a una hipótesis “beta” que nace del conocimiento que tiene el analista de negocio en su rubro específico.
Esto ayuda mucho a evitar encontrar correlaciones poco relevantes, como por ejemplo incrementos del bounce rate relacionados al incremento del tiempo medio en cada página.
Para aclarar la explicación de las correlaciones poco relevantes vamos a salir del contexto online brevemente y observar el siguiente cuadro:
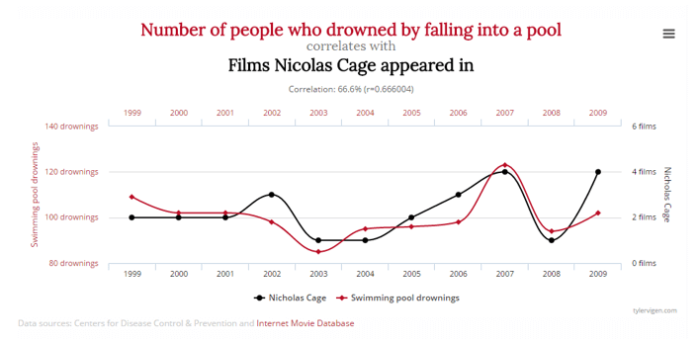
Observamos rápidamente que la cantidad de gente ahogada por caer a una piscina se relaciona directamente con la cantidad de películas donde aparece Nicolas Cage. Esto, a pesar de la ironía, no tiene sentido; sin embargo, los datos muestran que hay una correlación. Más ejemplos de correlaciones sin sentido se encuentran en el siguiente enlace: https://www.tylervigen.com/spurious-correlations
Para evitar caer en este tipo de cruces es preferible meditar previamente sobre qué tipo de variables se desean analizar con el fin de evitar trabajar en base a relaciones sin sentido.

Si este comic no termina de explicar que correlación no significa causación (no explica el comportamiento de ambas variables), estoy seguro que el siguiente gráfico lo hará:
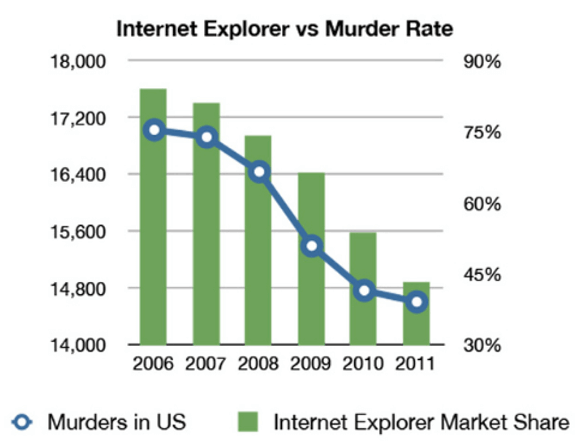

HIPÓTESIS
En base a los datos observados en el punto anterior tenemos una probable correlación entre Vistas de detalle de productos en el sitio y la cantidad de abandonos del embudo de conversión. Aún no sabemos si existe una relación de causalidad entre ambos, solo podemos afirmar que cuando uno aumenta, el otro también. Aquí es donde entran las pruebas de hipótesis.
Prueba de hipótesis, es un test estadístico que se usa para determinar si hay suficiente evidencia en los datos para inferir si el supuesto es válido para toda la población. Esta prueba necesita 2 hipótesis contradictorias: la hipótesis nula (Ho) y la hipótesis alternante (Ha).
Ho: La cantidad de abandonos del embudo no depende de la cantidad de vistas de detalle de producto.
Ha: La cantidad de abandonos del embudo depende de la cantidad de vistas de detalle de producto.
No voy a profundizar en este tema, ya que deseamos agilidad porque carecemos tiempo.
Para todo aquel que quiera entender más sobre las hipótesis pueden ver este video con una pésima canción, pero una muy buena explicación sobre las pruebas de hipótesis.
El mensaje más importante es que cuando uno mismo formula una hipótesis está prediciendo la respuesta a la pregunta que se quiere comprobar. (Una pista, en este caso que los abandonos se deben a la cantidad de vistas de productos).



REALIZAR EL EXPERIMENTO
Llegamos a la parte más entretenida.

Existen varias alternativas para trabajar datos, desde el viejo y conocido SPSS hasta el lenguaje opensource que está de moda “R” o “Python” con las librerías “numpy”, “pandas” y “matplotlib”, pero el objetivo de hoy es rapidez en el análisis por lo que vamos a usar Excel.
Para empezar, vamos a darle una vista rápida a los datos que hemos recolectado en base a nuestra experiencia como analistas de negocio con el fin de poder predecir los abandonos de embudos.
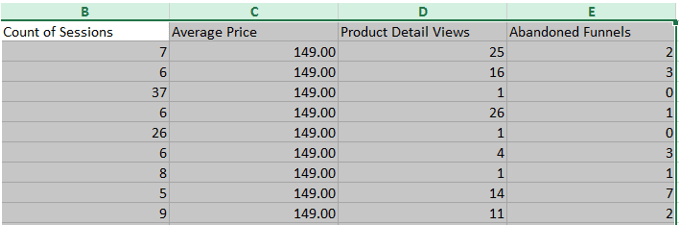
Nuestro dataset es pequeño, estamos trabajando con 2,767 observaciones.
Ahora vamos a describir que significa cada columna de datos.
- Columna E: Abandonos de embudos, suma los abandonos de embudo para cada observación (puede ser por cada fecha, hora, por cada sesión).
- Columna D: Product Detail Views, suma las veces que se ve una página de detalle de producto para cada observación.
- Columna C: Average Price
- Columna B: Count of Sessions, muestra la cantidad de visitas por cada observación.
Ahora vamos a validar si existe una correlación entre las variables mencionadas, considerar que Excel posee fórmulas para soportar estas pruebas estadísticas.
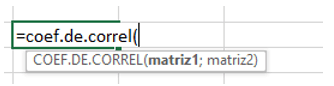
¿Alguien la recuerda? A mí me costó 5 intentos dar con la fórmula debido a que no recordaba que empezaba con “=coef.de…”
Excel tiene opciones de análisis de datos para situaciones como esta, donde se busca hacer un análisis preliminar o robusto, dependiendo del tiempo que se desee dedicar.

Si no lo encuentras probablemente sea necesario activarlo. En este enlace te llevo a un video donde paso a paso se puede activar el complemento de “Análisis de datos” (Analysis Toolpack, ya que el video está en inglés).
En caso no tengas tiempo para ver el video, los 3 pasos listados en texto están en este enlace (en español).
Ahora que tenemos activado el complemento, al abrirlo aparece un listado de todas las funciones que tiene.
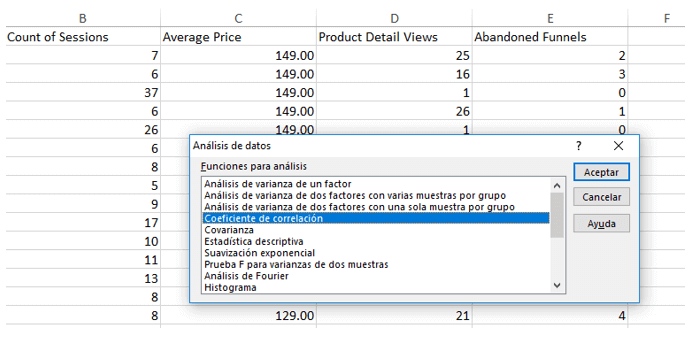
Como primer paso, vamos a usar la función de Coeficiente de correlación para cuantificar si hay una relación entre las variables que se usan.
Luego vamos a seleccionar todos los datos numéricos (no categóricos). Esto quiere decir que, si entre los datos descargados tengo, por ejemplo, fecha, canal de adquisición, nombre de campaña, grupo de anuncios, categoría de evento, etcétera, no los vamos a considerar en este tipo de análisis, ya que estos casos requieren un tratamiento especial.
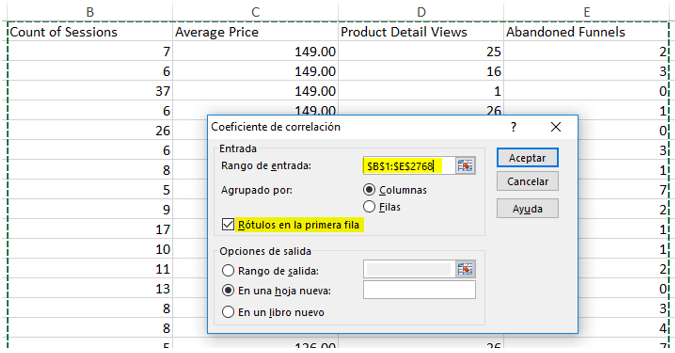
Falta poco, solo asegurarse activar la opción “Rótulos en la primera fila” si hay encabezados en las columnas de datos para evitar un mensaje de error.
Damos “Aceptar” y listo, en una hoja nueva nos va a salir la matriz de correlaciones.

¿Cómo debemos interpretar los datos?

Sencillo, el coeficiente tiene valores entre -1 (correlación negativa fuerte) y 1 (correlación positiva fuerte).
Ejemplo para correlación negativa fuerte (-1):
Cuando sube la temperatura caen las ventas de ropa de invierno.
Ejemplo para correlación positiva fuerte (-1):
Cuando sube la temperatura suben las ventas de ropa de baño.
Cero o valores cercanos implican que no hay relación entre ambas métricas.
Volviendo al tema:

Rápidamente vemos que hay un 0.95 (95% de relación) entre ¡Product Detail Views y Abandoned Funnels! Y no vemos relación significativa entre el resto de las variables.
Como ya sabemos que correlación no es causación, es decir, como no es comprobable que se puede predecir el comportamiento de los abandonos solo con ver los Product Detail Views, vamos a realizar la prueba estadística más rápida que nos pueda dar más luces en el tema.
Para ello vamos a volver a la opción de “Análisis de datos” en Excel.

Y seleccionamos “Regresión”:
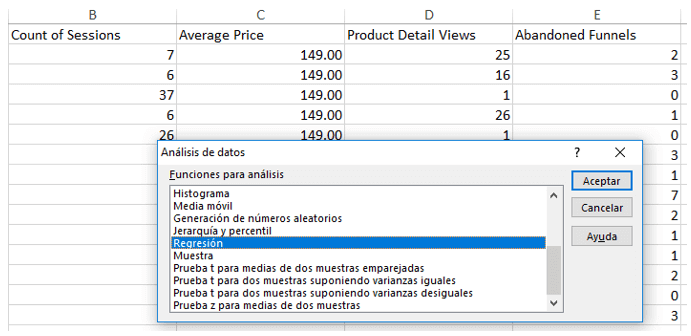
Con esta opción vamos a determinar si una combinación de Precio Promedio y Vistas de detalle de producto tiene una influencia en la cantidad de Abandonos del embudo de conversión.
Esto no lo estamos decidiendo subjetivamente (en base a la experiencia ni nada), el criterio es quedarnos con las variables que están relativamente relacionadas a los Abandonos de Embudo.
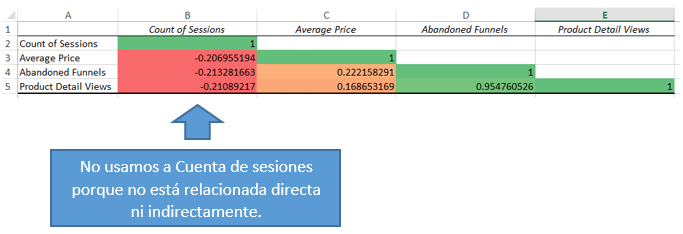
Entonces, en resumen, la regresión quedaría de la siguiente manera:
Abandonos del embudo = f (Precio medio + Vistas detalles de producto)
Esto se lee así: Los abandonos están en función al precio medio y las vistas de detalle de producto.
¿Por qué se lee así?
Porque queremos evaluar si los abandonos suben o bajan en función de cuantas veces se ve el detalle de vistas de producto en una sesión o si el precio medio de los productos afecta.

Para ello, seleccionamos todos los datos de la siguiente manera:
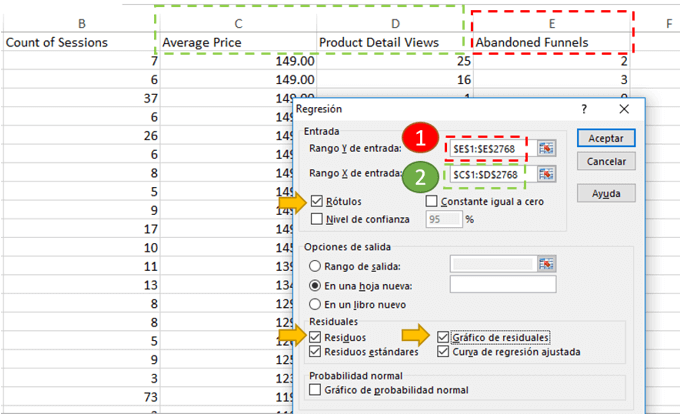
Le damos Aceptar y vamos a observar los resultados en una nueva hoja.
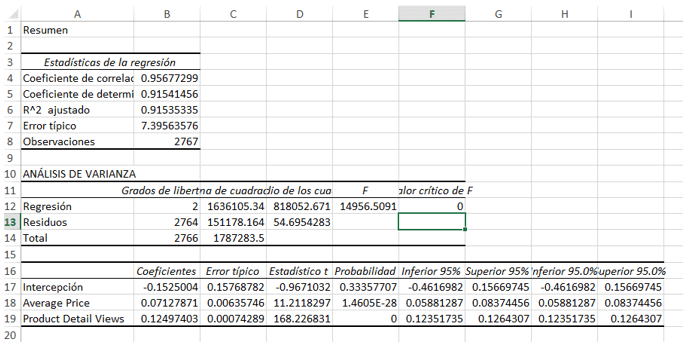

ANALIZAR LOS DATOS
Recordando el objetivo inicial de esta publicación, iremos al grano:
Resumen
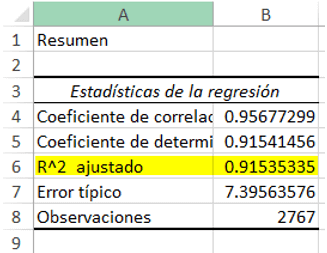
Nos conformamos con un R cuadrado ajustado alto, 91.5%. Este indicador nos dice que el modelo de regresión explica 91% de la varianza de los Abandonos de Embudo. Para ponerlo simple, nos dará un resultado certero en 9 de cada 10 intentos.
Debemos considerar que muchas veces no se logra alcanzar porcentajes tan altos, por lo que en determinados casos nos tenemos que conformar con un mínimo de 50%.
Análisis de Varianza
Con un Valor crítico menor a 0.05 podemos rechazar la hipótesis nula (Ho).

Otro nombre para Valor crítico es “p-valor” y el criterio de aceptación lo define cada analista en base a la siguiente escala:

Es decir, con esta prueba podemos afirmar con 95% de seguridad que la cantidad de Abandonos se debe a la cantidad de Vistas de detalle de producto en el sitio web y al Precio medio de los productos.
Visto de otro modo, podemos negar que la cantidad de Abandonos del embudo se dan por factores que no controlamos como el azar.
Con el mismo criterio en mente, la segunda parte del Análisis de Varianza nos da los valores críticos para cada variable.

En este caso, como ambas son menores a 0.05 (que es el error que estamos dispuestos a asumir para este modelo) seguimos considerándose.
Si una saliera mayor, simplemente volvemos a correr el análisis sin considerar la variable con una probabilidad mayor a 0.05.
Hemos llegado al punto donde con seguridad podemos extrapolar y hacer predicciones sobre el comportamiento de los usuarios.
¿Cómo?
Sugiero siempre pensar en el resultado deseado antes de emprender cualquier análisis.
Suponiendo que bajando los precios y manteniendo las Vistas de detalle de producto lograremos un impacto significativo en los abandonos.
Ahora a los números, vamos a ver los coeficientes del análisis de varianza.
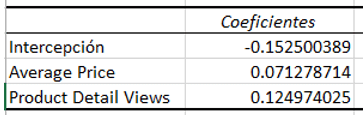
La fórmula se representa de la siguiente manera:
Promedio de abandonos = Intercepto + Coeficiente 1 x (Variable 1) + Coeficiente 2 x (Variable 2)
Considerando nuestros datos, la fórmula se ve del siguiente modo:
Promedio de abandonos = Intercepto + Coeficiente 1 x (Avg Price) + Coeficiente 2 x (Product Detail Views)
¿Qué valores vamos a incluir en Precio medio y Vistas de detalle de producto?
Los valores medios que obtuvimos en la etapa de observación, con eso vamos a tener el promedio real de abandonos de embudo.
Promedio de abandonos = -0.152500389 + 0.071278714 x (14) + 0.124974025 x (39)
Promedio de Abandonos reales = 5.7 = 6

Con esto podemos esperar un aproximado de 6 abandonos de sitio con la situación actual de nuestro negocio.
Al observar que el coeficiente de Product Detail Views es mayor, vamos a ver qué pasaría si reducimos la cantidad de Product Detail Views a 10.
Volviendo a jugar con la fórmula, vamos a suponer que mejoramos la experiencia de usuario en la plantilla de Detalle de producto de la tienda online reduciendo el promedio de vistas a 10:
Abandonos esperados = -0.152500389 + 0.071278714 x (14) + 0.124974025 x (10)
Abandonos esperados = 2
¿Qué acabamos de ver?
Lo que la fórmula nos indica es que para mejorar el performance del flujo de conversión de este negocio online, alterar el precio no tiene tanto impacto como optimizar la experiencia en las páginas de los productos (detalles).



REPORTAR LOS HALLAZGOS
Cómo presentar los insights depende de dos puntos:
- Las variables usadas para armar el modelo estadístico.
- El enfoque del analista para presentar la oportunidad de negocio.

Considera usar el sentido común en base a tu experiencia antes de solo guiarte de la información.
Como conclusión vamos a apoyarnos en la data para tomar decisiones con seguridad que tengan impacto en los objetivos estratégicos del negocio al que formamos parte.

INVITAR A OTROS A REPRODUCIR LOS RESULTADOS
Felicidades si llegaron hasta esta parte, hagamos que el tiempo invertido no sea en vano por lo que les reto a tomarse un tiempo para hacer un poco de análisis y compartir sus resultados comentando sus experiencias.
Recordemos que los insights que se logren de este tipo de análisis no necesitan tener un alto grado de significancia estadística, como si se requiere en medicina o en rubros de alimentos, maquillaje, etc. donde existe un riesgo contra la salud de los pacientes o clientes.

En la venta digital somos más arriesgados puesto que una acción que pueda generar una venta por ejemplo en el 50% de veces que se intente, se considera un gol de media cancha.
Con el fin de llegar al objetivo secundario propuesto al inicio de este artículo les comparto los tiempos.
Objetivo secundario
El modelo tiene que ser un Producto Mínimo Viable; es decir, el modelo tiene que ser estadísticamente significativo pero no se va a optimizar ni buscar la mejor alternativa para evaluar los datos y se tiene que entregar en la mínima cantidad de tiempo posible. Le dejaremos esta parte a los de BI.
- 16 horas dedicado a realizar, validar y analizar correlaciones y regresiones de variables de Google Analytics.
- 1 hora concluyendo que los abandonos pueden ser explicados por una combinación del precio medio y vistas de detalle de producto.
- 6 horas escribiendo esta publicación.
Queda claro y no puedo negar que hay muchos pasos para refinar el análisis y presentar resultados más robustos, pero los hemos sacrificado en este caso para cumplir el objetivo de presentar un Producto Mínimo Viable que nos permita avanzar a la velocidad que lo permiten los negocios actualmente.
CONCLUSIONES
Hemos visto un concepto básico, una introducción a lo que es el User Testing y que poco a poco he ido desarrollando para darte una idea fresca de cómo se desarrolla.
Sin embargo, todavía hay puntos que tratar, por eso te invito a descubrir cómo se prepara y ejecuta el user testing considerado como la segunda parte de este tema. Allí expongo mi punto de vista y experiencia ¿te animas a verlo?
¿ESTÁS PENSANDO EN USER TESTING? PONTE EN CONTACTO CON NOSOTROS. EN ATTACH TE AYUDAMOS CON TU PROYECTO!
TEMAS: Google Analytics

